第2章 第2节 Embedding(二)-词向量的魔法
第2章 第2节 Embedding(二)-词向量的魔法
阅读指南
上一节看到了Embedding如何用低维稠密向量替代高维稀疏向量。但这些向量有什么神奇的性质?本节将看到,词向量竟然能做代数运算,而且模型是如何自动学习这些语义表示的。
2.1 Embedding的神奇性质
词向量的代数运算
一个令人惊叹的现象:
Embedding(国王) - Embedding(男人) + Embedding(女人) ≈ Embedding(女王)
这是2013年Mikolov等人在Word2Vec论文中展示的真实实验结果。
Note
这个著名的类比关系源自Google的Word2Vec项目,出自Tomas Mikolov等人于2013年发表的《Efficient Estimation of Word Representations in Vector Space》。
"国王"这个词的向量,减去"男性"的成分,再加上"女性"的成分,得到的结果非常接近"女王"的向量。词也可以做加减运算。
向量空间中的几何解释
想象一个三维空间(实际是12288维,简化成3维来可视化):
词 X:性别 Y:权力 Z:年龄 说明
─────────────────────────────────────────────────
国王 5 10 3 男性(5)、权力很高(10)、较年长(3)
男人 5 0 0 男性(5)、无权力(0)、年龄中等(0)
女人 -5 0 0 女性(-5)、无权力(0)、年龄中等(0)
女王 -5 10 3 女性(-5)、权力很高(10)、较年长(3)
做数学运算:
国王 - 男人 = [5, 10, 3] - [5, 0, 0] = [0, 10, 3] ← 去掉"男性"属性
[0, 10, 3] + 女人 = [0, 10, 3] + [-5, 0, 0] = [-5, 10, 3] ← 加上"女性"属性
[-5, 10, 3] = 女王 ✓
向量的减法提取了"概念之差"。国王减男人等于"具有权力的人,去掉男性属性",也就是"权力"这个抽象概念。女人加上"权力"等于具有权力的女性,即女王。
更多令人惊叹的例子
1. 动物-栖息地关系
Embedding(鱼) - Embedding(水) + Embedding(天空) ≈ Embedding(鸟)
鱼减去水等于"某种生物去掉它的栖息地",也就是"生物实体"。生物实体加上天空等于"在天空中生活的生物",即鸟。
2. 语法关系(时态)
Embedding(走) - Embedding(走了) + Embedding(吃了) ≈ Embedding(吃)
走减去走了等于"动词减去它的过去式",也就是"时态转换"。吃了加上逆向时态转换等于吃。
3. 语义关系(反义词)
Embedding(大) - Embedding(小) + Embedding(长) ≈ Embedding(短)
大减小等于"一对反义词的关系",即"反义关系向量"。长加上反义关系向量等于长的反义词,即短。
语言的内在结构
这个现象揭示了一个深刻的事实:
语言不是随机的符号堆砌,而是有内在的数学结构的。时态关系、栖息地关系、比较关系,这些关系都被编码成了向量,而Embedding把这个隐藏的结构显现出来了。
哲学性的思考
语言学家索绪尔的观点:词的意义来自于它与其他词的差异关系。
"苹果"的意义不是孤立的,而是它与"香蕉"的差异(都是水果)、与"红色"的关系(颜色属性)、与"吃"的关系(动词搭配)、与"甜"的关系(味道)。这些关系,在Embedding中被编码为向量间的距离和方向。
Embedding不仅是技术,更是语言哲学的数学实现。它证明了:意义是关系,关系可以被数学化,语言可以被几何化。
2.2 Embedding的学习机制
Embedding是怎么学出来的?
这12288个数字到底是怎么得到的?答案是:它们是训练出来的。
还记得语言模型的任务吗?预测下一个词。
输入:"猫喜欢吃____"
目标:预测下一个词是"鱼"(概率高)还是"电脑"(概率低)
为了完成这个任务,模型必须知道"猫"和"鱼"有关联。这个关联,就编码在Embedding里。
1. 初始化
一开始,每个词的Embedding是随机的:
猫 = [0.01, -0.03, 0.05, ...] ← 随机数字,没有意义
鱼 = [0.02, 0.01, -0.04, ...] ← 随机数字,没有意义
2. 训练
模型在数百万篇文本中,看到了无数次"猫吃鱼"的例子,每看到一次,就调整Embedding:
看到"猫喜欢吃鱼" → 调整"猫"和"鱼"的Embedding,让它们更相似
看到"猫抓老鼠" → 调整"猫"和"老鼠"的Embedding
看到"狗喜欢跑" → 调整"狗"和"跑"的Embedding
3. 收敛
经过数千万次调整,Embedding逐渐稳定:
词 训练后向量 语义关系
────────────────────────────────────────────────────────
猫 [0.2, -0.5, 0.7, ...] 编码了"猫"的语义
鱼 [0.15, -0.48, 0.65, ...] 与"猫"相近(常一起出现)
狗 [0.18, -0.52, 0.68, ...] 与"猫"相近(都是动物)
电脑 [-0.3, 0.6, -0.1, ...] 与"猫"很远(完全不同类)
4. 最终结果
当模型再次看到"猫喜欢吃____",它计算:
P(鱼 | 猫喜欢吃) = 0.35 ← 高,因为"猫"和"鱼"的Embedding相近
P(电脑 | 猫喜欢吃) = 0.001 ← 低,因为"猫"和"电脑"的Embedding很远
Embedding不是人工设计的,而是为了完成"预测下一个词"这个任务,模型自动发现:
- 哪些词常常一起出现
- 哪些词有相似的用法
- 哪些词有相似的语义
然后把这些"发现"编码进了Embedding的12288个数字里。
ChatGPT中的Embedding:从词到句子
ChatGPT处理文本的完整流程:
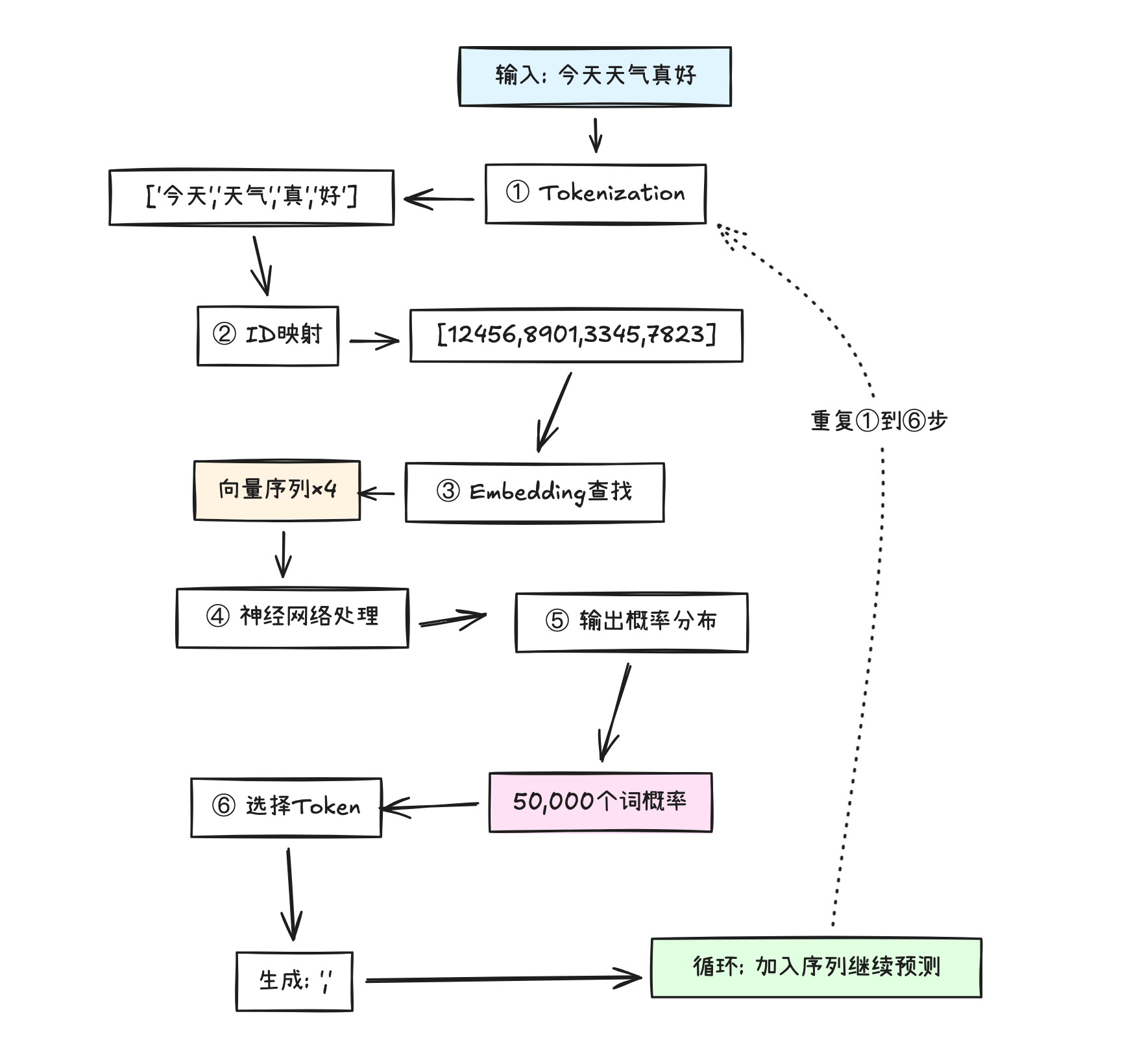
1. Tokenization(分词)
输入的文字被切分成token:
"今天天气真好" → ["今天", "天气", "真", "好"]
2. Token ID映射
每个token映射到一个整数ID:
"今天" → 12456
"天气" → 8901
"真" → 3345
"好" → 7823
Note
为什么需要ID?因为计算机不能直接处理文字,必须先转成数字。每个词在词表中有一个唯一的ID号。
3. Embedding查找
根据ID查询对应的Embedding向量:
12456 → [0.23, -0.45, 0.67, ..., 0.12] ← 12288维
8901 → [0.34, -0.12, 0.45, ..., 0.23] ← 12288维
3345 → [-0.12, 0.56, -0.34, ..., 0.45] ← 12288维
7823 → [0.45, 0.23, -0.67, ..., -0.12] ← 12288维
ChatGPT内部有一个巨大的"Embedding表",用ID号一查,就能拿到对应的12288维向量。
4. 输入Transformer
这些向量作为输入,送进Transformer网络:
[
[0.23, -0.45, ..., 0.12], ← "今天"
[0.34, -0.12, ..., 0.23], ← "天气"
[-0.12, 0.56, ..., 0.45], ← "真"
[0.45, 0.23, ..., -0.12] ← "好"
]↓
Transformer处理(Self-Attention, FFN, ...)
↓
输出:50000个词的概率分布
5. 预测下一个token
根据概率分布,选择下一个token,比如","(ID=566)。
6. 循环
把新生成的token加入序列,重复上述过程:
["今天", "天气", "真", "好", ","] → 预测下一个
Embedding是连接符号世界(文字)和数值世界(计算)的桥梁。
Embedding参数与总参数的关系
Embedding层的参数本身就包含在1750亿参数里面。
假设GPT-3:
- 词表大小:50000个词
- Embedding维度:12288
Embedding层参数量 = 50000 × 12288 = 6.144亿参数
这6.144亿参数是1750亿参数的一部分(约0.35%),剩下的1743多亿参数分布在注意力层的权重矩阵、前馈神经网络的权重矩阵、层归一化的参数、输出层的权重等。
Embedding层学会语义表示,其他层学会语言规律,它们在训练中一起被优化,不是分开的两个过程。
2.3 下一节预告
现在知道了Embedding的神奇性质和学习机制。但这背后隐藏着一个更深刻的问题:这些数字真的代表"意义"吗?
下一节将从哲学角度思考:什么是"猫"?符号、数字、关系,哪一个才是真正的意义?同时还会看到一些有趣的词向量实验。
2.4 ■ 学点英语
| 中文 | English | 音标 | 说明 |
|---|---|---|---|
| 词向量 | Word Vector | /wɜːd ˈvektər/ | 用数值向量表示词的语义,语义相近的词向量距离近 |
| 词向量 | Word Embedding | /wɜːrd ɪmˈbedɪŋ/ | 用数值向量表示词的语义,语义相近的词向量距离近 |
| 语义代数 | Semantic Algebra | /sɪˈmæntɪk ˈældʒɪbrə/ | 词向量可做加减运算的性质,如国王-男人+女人≈女王 |
| 类比推理 | Analogy Reasoning | /əˈnælədʒi ˈriːzənɪŋ/ | 通过向量运算发现词间关系模式的能力 |
| 词嵌入层 | Embedding Layer | /ɪmˈbedɪŋ ˈleɪər/ | 神经网络中将Token ID映射为稠密向量的参数层 |
| 嵌入表 | Embedding Table | /ɪmˈbedɪŋ ˈteɪbl/ | 存储所有Token的Embedding向量的查找表 |
| 语义编码 | Semantic Encoding | /sɪˈmæntɪk ɪnˈkəʊdɪŋ/ | 将词的定义关系编码为向量空间中的位置和方向 |
| 共现关系 | Co-occurrence | /koʊ əˈkɜːrəns/ | 两个词在文本中经常一起出现,是Embedding学习的核心信号 |